
快速排序
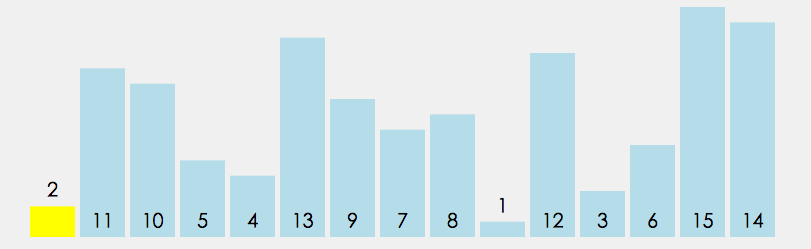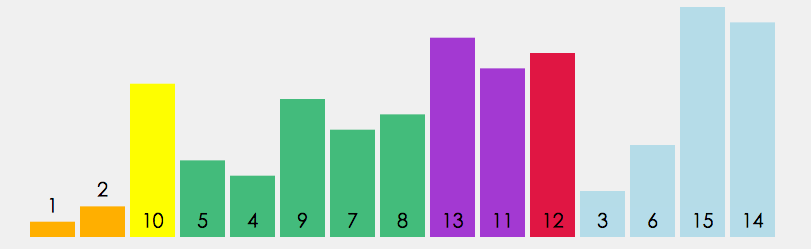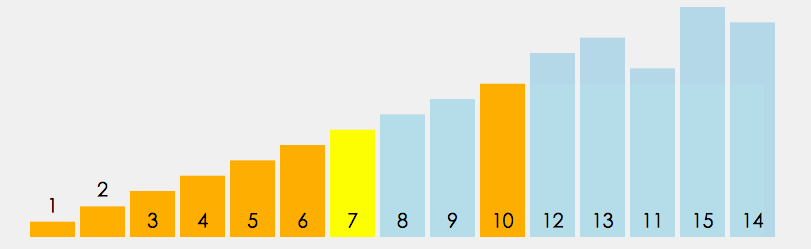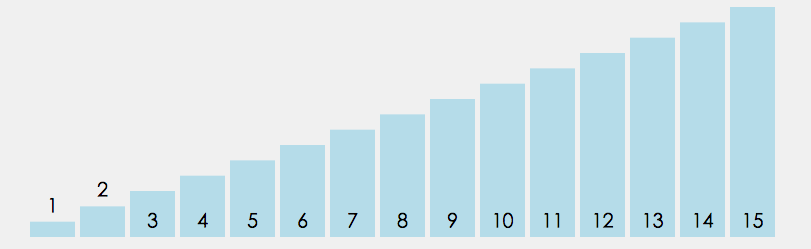
/** * 快速排序(递归) * * 1. 从数列中挑出一个元素,称为"基准"(pivot)。 * 2. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。 * 3. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。 * @param arr 待排序数组 * @param low 左边界 * @param high 右边界 */ public static void quickSort(int[] arr, int low, int high){ if(arr.length <= 0) return; if(low >= high) return; int left = low; int right = high; int temp = arr[left]; //挖坑1:保存基准的值 while (left < right){ while(left < right && arr[right] >= temp){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中 right--; } arr[left] = arr[right]; while(left < right && arr[left] <= temp){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中 left++; } arr[right] = arr[left]; } arr[left] = temp; //基准值填补到坑3中,准备分治递归快排 System.out.println("Sorting: " + Arrays.toString(arr)); quickSort(arr, low, left-1); quickSort(arr, left+1, high); }- 平均时间复杂度最好情况最坏情况空间复杂度
Last updated